Demystifying Deep Learning: Part 9
Backpropagation in a Convolutional Neural Network
September 10, 2018
6 min read


Introduction
In this post, we will derive the backprop equations for Convolutional Neural Networks. Again there is a Jupyter notebook accompanying the blog post containing the code for classifying handwritten digits using a CNN written from scratch.
In a feedforward neural network, we only had one type of layer (fully-connected layer) to consider, however in a CNN we need to consider each type of layer separately.
The different layers to consider are:
- Convolution Layer
- ReLU Layer
- Pooling Layer
- Fully-Connected Layer
- Softmax (Output) Layer
If you are not already comfortable with backpropagation in a feedforward neural network, I’d suggest looking at the earlier post on Backpropagation which contains some useful intuition and general principles on how to derive the algorithm.
I’ll restate the general principles here for convenience:
Partial Derivative Intuition: Think of loosely as quantifying how much would change if you gave the value of a little “nudge” at that point.
Breaking down computations - we can use the chain rule to aid us in our computation - rather than trying to compute the derivative in one fell swoop, we break up the computation into smaller intermediate steps.
Computing the chain rule - when thinking about which intermediate values to include in our chain rule expression, think about the immediate outputs of equations involving - which other values get directly affected when we slightly nudge ?
One element at a time - rather than worrying about the entire matrix , we’ll instead look at an element . One equation we will refer to time and time again is:
A useful tip when trying to go from one element to a matrix is to look for summations over repeated indices (here it was k) - this suggests a matrix multiplication.
Another useful equation is the element-wise product of two matrices:
Sanity check the dimensions - check the dimensions of the matrices all match (the derivative matrix should have same dimensions as the original matrix, and all matrices being multiplied together should have dimensions that align.
Convolution Layer
Recall that the forward pass’ equation for position in the activation map in the convolution layer is:
Since a convolution cannot be represented as a matrix multiplication, we will just consider a single neuron/weight at a time.
Just like with a standard feedforward neural net, a nudge in the weights results in a nudge in corresponding to the magnitude of the input it is connected to. A nudge in the bias has the corresponding magnitude in .
So considering our single neuron and a weight the corresponding input is from the forward prop equation above. So:
It helps to refer back to the equivalent neurons representation of a convolution for the . Since the weights/bias are shared, we sum partial derivatives across all neurons across the width and the height of the activation map, since a nudge in the weights/bias will affect the outputs of all neurons.
We also average the gradient across the batch of training examples.
So the backprop equations for the weights and bias are, using chain rule:
So the equations for the partial derivatives with respect to the weights and biases are fairly similar to that of a feedforward neural net, just with parameter sharing.
Now we need to compute the partial derivative with respect to the input so we can propagate the gradient back to the previous layer. This is a little more involved.
Firstly, note that a nudge in the input affects all of the activation maps, so we sum across the activation maps. So now let’s consider the activation map.
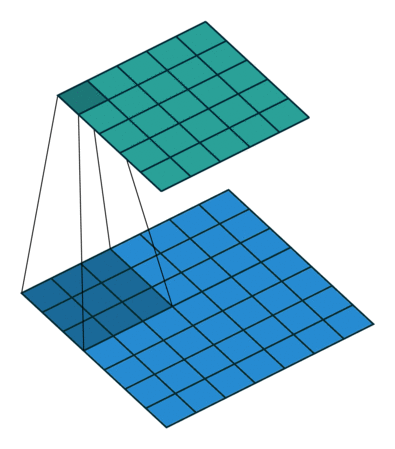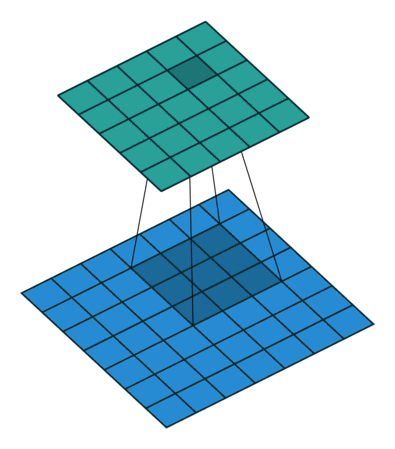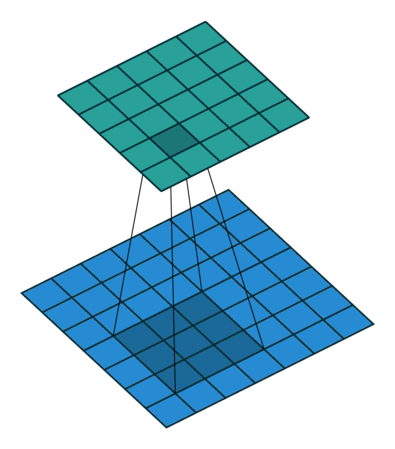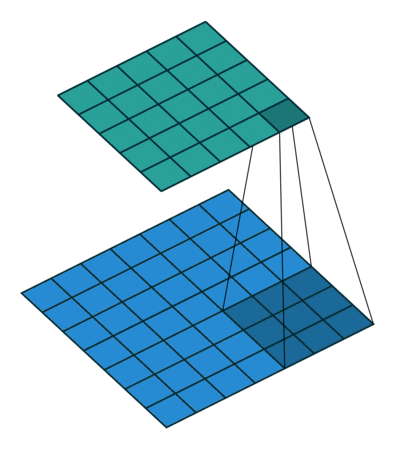
Now consider the representation of the convolution as a sliding filter operation. The filter slides over the input across the height and width dimensions so for a given input pixel , there are different outputs it is part of, depending on which part of the filter has scanned over it ( is the filter size). To determine the corresponding output patch when is multiplied by , note that in the forward pass, for the corresponding input is offset by relative to the output (see equation), so from the perspective of the input, the output is offset by . So given an input and weight the corresponding output is .
So the equation is:
Note that this is actually itself a convolution! When implementing, we need to zero-pad the output, since around the edges, the indices (i-a,j-b) may be negative (i.e. does not exist) - so we set these values to zero, as non-existent values shouldn’t contribute to the sum of the gradients.
Code:
When implementing, we broadcast and vectorise the operations when calculating the gradient with respect to and .
def conv_backward(dZ,x,w,padding="same"):m = x.shape[0]db = (1/m)*np.sum(dZ, axis=(0,1,2), keepdims=True)if padding=="same":pad = (w.shape[0]-1)//2else: #padding is valid - i.e no zero paddingpad =0x_padded = np.pad(x,((0,0),(pad,pad),(pad,pad),(0,0)),'constant', constant_values = 0)#this will allow us to broadcast operationsx_padded_bcast = np.expand_dims(x_padded, axis=-1) # shape = (m, i, j, c, 1)dZ_bcast = np.expand_dims(dZ, axis=-2) # shape = (m, i, j, 1, k)dW = np.zeros_like(w)f=w.shape[0]w_x = x_padded.shape[1]for a in range(f):for b in range(f):#note f-1 - a rather than f-a since indexed from 0...f-1 not 1...fdW[a,b,:,:] = (1/m)*np.sum(dZ_bcast*x_padded_bcast[:,a:w_x-(f-1 -a),b:w_x-(f-1 -b),:,:],axis=(0,1,2))dx = np.zeros_like(x_padded,dtype=float)Z_pad = f-1dZ_padded = np.pad(dZ,((0,0),(Z_pad,Z_pad),(Z_pad,Z_pad),(0,0)),'constant', constant_values = 0)for m_i in range(x.shape[0]):for k in range(w.shape[3]):for d in range(x.shape[3]):dx[m_i,:,:,d]+=ndimage.convolve(dZ_padded[m_i,:,:,k],w[:,:,d,k])[f//2:-(f//2),f//2:-(f//2)]dx = dx[:,pad:dx.shape[1]-pad,pad:dx.shape[2]-pad,:]return dx,dW,db
ReLU Layer
Recall that . When this returns so this is linear in this region of the function (gradient is 1), and when this is always 0 (so a constant value), so gradient is 0. NB the gradient at exactly 0 is technically undefined but in practice we just set it to zero.
Code:
def relu(z, deriv = False):if(deriv): #this is for the partial derivatives (discussed in next blog post)return z>0 #Note that True=1 and False=0 when converted to floatelse:return np.multiply(z, z>0)
Pooling Layer
For the pooling layer, we do not need to explicitly compute partial derivatives, since there are no parameters. Instead we are concerned with how to distribute the gradient to each of the values in the corresponding input 2x2 patch.
there are two options:
- Max Pooling
- Average Pooling

Max Pooling:
Intuitively a nudge in the non-max values of each 2x2 patch will not affect the output, since the output is only concerned about the max value in the patch. Therefore the non-max values have a gradient of 0.
For the max value in each patch, since the output is just that value, a nudge in the max value will have a corresponding magnitude nudge in the output - so the gradient is 1.
So effectively, we are just routing the gradient through only the max value of that corresponding input patch.
Average Pooling:
Here for a given 2x2 patch the output is given by the mean of the values i.e:
Thus a nudge in any of these values in the patch will have a output nudge that is only a quarter of the magnitude - i.e. the gradient here is 0.25 for all values across the image.
Intuitively think of this as sharing the gradient equally between the values in the patch.
Code:
It is worth bringing up the code from the forward pass, to detail how the mask, which is used to allocate gradients, is created.
Max Pooling:
We use np.repeat() to copy one ouput value across the corresponding 2x2 patch (i.e. we double the width/height of the output) - so it has the same dimensionality as the input.
To get the position of the max element in the patch, rather than doing an argmax, a simple trick is to elementwise compare the input with the scaled up output, since the output is only equal to the max value of the patch.
One subtlety with floating point multiplication is that we can get floating point rounding errors, so we use np.isclose() rather than np.equal() to have a tolerance for this error.
We then convert the mask to int type explicitly, to be used in the backward pass - so it zeros the gradient for the non-max values.
Average Pooling:
Here the gradient is just 0.25 for all values, so we create a mask matrix of the same dimensionality of all 0.25s.
For the backward pass, we scale the gradient matrix up by copying the value of the gradient for each patch to all values in that 2x2 patch, then we allocate gradients by applying the pre-computed mask in the forward pass.
def pool_forward(x,mode="max"):x_patches = x.reshape(x.shape[0],x.shape[1]//2, 2,x.shape[2]//2, 2,x.shape[3])if mode=="max":out = x_patches.max(axis=2).max(axis=3)mask =np.isclose(x,np.repeat(np.repeat(out,2,axis=1),2,axis=2)).astype(int)elif mode=="average":out = x_patches.mean(axis=3).mean(axis=4)mask = np.ones_like(x)*0.25return out,mask#backward calculationdef pool_backward(dx, mask):return mask*(np.repeat(np.repeat(dx,2,axis=1),2,axis=2))
Fully-Connected Layer
The fully-connected layer is identical to that used in the feedforward neural network, so we will skip the derivation (see original backprop post and just list the equations below.
The code is the same as the feedforward network layer, so again we’ll just list it below:
def fc_backward(dA,a,x,w,b):m = dA.shape[1]dZ = dA*relu(a,deriv=True)dW = (1/m)*dZ.dot(x.T)db = (1/m)*np.sum(dZ,axis=1,keepdims=True)dx = np.dot(w.T,dZ)return dx, dW,db
Softmax Layer:
The equation we are concerned with computing is:
The rest of the equations for the output layer are identical to the fully-connected layer, since the softmax layer only differs in activation function.
Recall that the cost function is the cross-entropy cost function:
Again, we can consider a single output layer node - so consider the node corresponding to the training example and the class, .
Next we consider the effect of nudging the weighted input of tehe output code corresponding to the training example and the class, .
Recall the equation for the softmax layer:
Clearly a nudge in will affect the value of the corresponding output node since we exponentiate in the numerator.
However, there is another subtletly. Since the nudge affects the value , it will affect the sum of the exponentiated values, so it will affect the outputs of all of the ouput nodes, since the denominator of all nodes is the aforementioned sum of the exponentiated values.
Let’s consider the two cases separately.
First, let’s compute the derivative of the output of the corresponding output with respect to - we use quotient rule since both the numerator and denominator are dependent on .
Next, consider the derivative of a different node with respect to . Here the numerator doesn’t depend on since we have exponentiated a different node .
So the derivative is just:
Since , and a nudge in affects all output nodes, we sum partial derivatives across nodes, so using chain rule we have:
Again, we split into the two cases:
\frac{\partial{J}}{\partial{z^{(i)[L]}_j}} = \frac{-y^{(i)}\_j}{\hat{y}^{(i)}\_j} \* \hat{y}^{(i)}\_j(1 - \hat{y}^{(i)}\_j) + \sum_{k \neq j} \frac{-y^{(i)}\_k}{\hat{y}^{(i)}\_k} _- \hat{y}^{(i)}\_j_\hat{y}^{(i)}\_k
Tidying up and combining the term with the term to get :
Since the probabilities of across the output nodes sum to 1, this reduces our equation to:
So wrapping up, having considered the equation for one neuron, we can generalise across the matrix to get:
Code:
def softmax_backward(y_pred, y, w, b, x):m = y.shape[1]dZ = y_pred - ydW = (1/m)*dZ.dot(x.T)db = (1/m)*np.sum(dZ,axis=1,keepdims=True)dx = np.dot(w.T,dZ)return dx, dW,db
Conclusion:
This wraps up our discussion of convolutional neural networks. CNNs have revolutionised computer vision tasks, and are more interpretable than standard feedforward neural networks as we can visualise their activations as images (see start of post). We look at the activations in more detail in the notebook.
Next we will look at another specialised class of neural networks - recurrent neural networks, which are optimised for input sequences (e.g sentences for NLP).

